Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
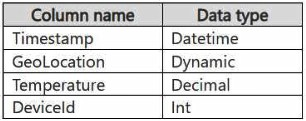
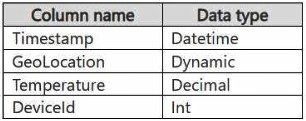
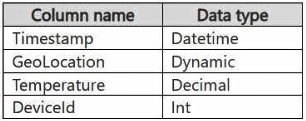
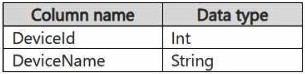
You have a KQL database that contains two tables named Stream and Reference. Stream contains streaming data in the following format.
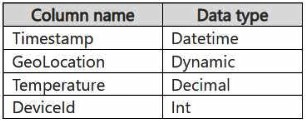
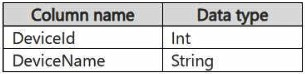
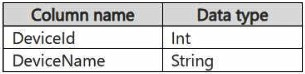
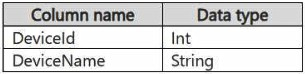
Reference contains reference data in the following format.
Both tables contain millions of rows.
You have the following KQL queryset.

You need to reduce how long it takes to run the KQL queryset.
Solution: You add the make_list() function to the output columns.
Does this meet the goal?